
前回は「ポインタとはアドレスを扱う変数である」という説明をした。
今回はポインタを使って何ができるのかについて説明していく。
もくじ
値の読み書き
次のコードを実行してみよう。結果はどうなるだろうか。
#include <stdio.h>
int main(void){
int a = 123;
int* p = &a; // (1)
printf("%d", *p); // (2)
}「123」が表示されたと思う。
p は、int型の変数 a のアドレスを持つポインタだけど、printfの行で *p という使われ方をしている。
ポインタ p はアドレス、 *p は「そのアドレスにある値」である。
p は変数 a のアドレスなので、この場合
p は &a のことである。
*p は a のことである。
ポインタを宣言するときと * の使い方が違う。
ポインタの * には、次の2つの使い方があるのだ。
- ポインタの宣言
- そのアドレスにある値を使う
先ほどのコードの(1)は「ポインタを宣言する」使い方で、(2)は「そのアドレスにある値を使う」使い方だ。同じ記号だけど使い方がまったく異なるので混同しないように注意が必要だ。
次のコードを実行したらどうなるだろうか。
#include <stdio.h>
int main(void){
int a = 123;
int* p = &a;
*p = 124;
printf("%d", a);
}*p に対して数値の124を代入し、変数 a の値をprintfで表示している。
この場合、p が持つアドレスには変数aの値があるので、*p に値を代入するということは、変数 a に値を代入することに等しい。
結果は124となるはずだ。
+、-の計算
ポインタは加減算ができる。(掛け算・割り算は不可)
次の2つのコードを実行してみよう。
#include <stdio.h>
int main(void){
int arr[3] = {100, 101, 102};
int* p = &arr[0];
printf("%d\n", *p);
p++;
printf("%d\n", *p);
p++;
printf("%d\n", *p);
}#include <stdio.h>
int main(void){
int arr[3] = {100, 101, 102};
int* p = &arr[0];
printf("%d\n", *p);
printf("%d\n", *(p + 1));
printf("%d\n", *(p + 2));
}実はこれらはいずれも次の結果を表示する。
100
101
102ポインタを加減算することには例えば次のような意味がある。
int型のポインタ(int*型)を+1すると、int型のサイズ分(4バイト)だけアドレス値を加算する。
double型のポインタ(double*型)を+1すると、double型のサイズ分(8バイト)だけアドレス値を加算する。
char型のポインタ(char*型)を+1すると、char型のサイズ分(1バイト)だけアドレス値を加算する。
ポインタを -1 すると、逆にアドレス値を減算する。
このように、ポインタの型によって加減算の結果は異なる。int*とdouble*は別物なのだ。
参照渡し
実は、これがポインタの一番のメリットといってもよい。
例えば、次のような巨大な構造体があるとする。
struct _ST_DATA
{
int x;
int y;
// 他、ここでは書ききれないくらいメンバがたくさんある。
} typedef ST_DATA;このような巨大な構造体を関数に渡して色々計算したい、という場面は結構多い。こんな風に。
void Func(ST_DATA data)
{
// dataを使って色々計算する。
}ここで一つ問題が起こる。
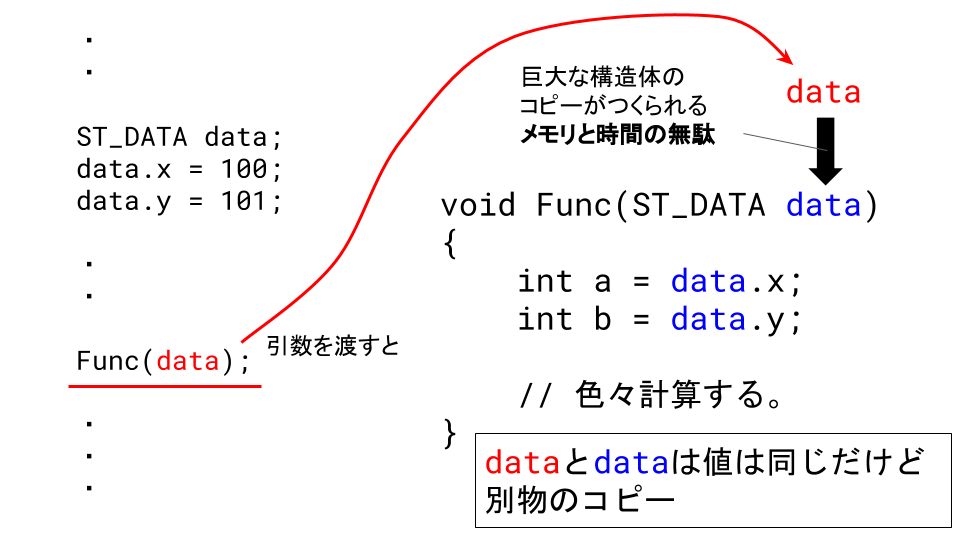
関数に引数を渡すとき、渡した引数はそのまま関数内で使われる訳ではない。
渡されたものと同じ値のコピーを作ってからそれを関数内で使うというということが行われる。
引数が何MBもあるような巨大なものだとどうなるか。
関数が呼び出される度に何MBもの値のコピーが作られ、関数の実行が終わったらそれが破棄される、ということが行われる。
プログラムによっては関数の呼び出しは1秒間に何十回、ものによっては何百、何千回にだってなる。
そうなるとプログラムの実行がとても重くなる。メモリの消費量も毎回何MBか無駄になる。
プログラムを使っているユーザーが処理結果を見るまで何十秒も待たされたり、画面がなめらかに動かなくなったりして、ろくなことがない。
だから、効率的なプログラムが必要だ。
そんなときにポインタが活躍する。
先ほどの関数を次のように直してみる。
void Func(ST_DATA* pData)
{
// pDataを使って色々計算する。
}
ST_DATAという構造体は巨大だけど、この関数の引数はポインタとなっている。つまり構造体のアドレスだ。
アドレスのサイズはどのくらいだっただろうか。
前回ちらっとだけ説明したけど、64bitのPCでは8バイト、32bitのPCでは4バイトだ。
アドレスを扱うだけだからかなり小さく済む。
メモリの使用量は少ないし、関数の呼び出しも短時間で済む。
このように、アドレスを引数に渡すことは参照渡しと呼ばれている。これに対し、普通に値を引数に渡すことは値渡しと呼ばれている。
値渡しの場合、関数を呼び出すときに引数に渡した値と、関数内で使われる値はコピーであり、メモリの別々の位置に存在するため、一方を書き換えてももう一方には何ら影響はない。
これに対し、参照渡しの場合、関数の引数に渡されるのはアドレスなので、アドレスの指す場所にある変数の値を関数内で書き換えると、関数を呼び出した側に存在する変数の値も書き換わるという違いがある。
ところで、さりげなく登場した「pData->x」という記述だけど、これはポインタを使うとき特有の書き方だ。
普通に構造体のメンバを使うときは「data.x」などと書くけど、ポインタから直接構造体のメンバを使うときには「pData->x」と書く、というだけの話だ。
「->」は、ハイフンと不等号で書けばよい。矢印に見えることから「アロー演算子」と呼ばれている。